


 VS Code用のEchoAPI
VS Code用のEchoAPI

 IntelliJ IDEA用のEchoAPI
IntelliJ IDEA用のEchoAPI

 EchoAPl-Interceptor
EchoAPl-Interceptor

 EchoAPl CLI
EchoAPl CLI
 APIデザイン
APIデザイン
 APIデバッグ
APIデバッグ
 APIドキュメント
APIドキュメント
 Mockサーバー
Mockサーバー






API優先が私たちのフロントエンド・バックエンド統合を混沌から明確さへと導いた方法
ソフトウェア開発では、APIの管理が整わない在り方から生じるカオスを回避し、EchoAPIを活用したAPIファーストアプローチで明確さと効率性を実現します。


数ヶ月前に、我がチームはまさしく「伝説的 API 爆死劇」を体験した。お前もそこにいたかもしれねえ — フロントエンドがバックエンドを待つ、フィールド名がスプリント中に勝手に変わる、データ構造がポケモン並みに突然進化してく… でも、そのとき总算理解したんだ。
API優先なしで、製品開発は目隠しをしたまま地雷原を走るようなものだ。
私たちは、ユーザーが時間、行動、地域などに基づいて活動トレンドを表示できるユーザーインサイトダッシュボードという新しい機能を開発していました。月曜日にPMがfrivolously言いました。
「ユーザー一覧APIの構造を再利用するだけで、3日で終わる任务だろう。」
フロントエンドは慌てて UI を構築。
バックエンドは焦ってロジックを書き始める。そして、遂に「おぞましい大阪天満宮の例大祭の「神輿ESISDay」」が访れる…
- フロントエンド:「待って…このフィールドはオブジェクトなのか配列なのか?前回のモックと一致しないよ。」
- バックエンド:「なぜこんなにネストしているの?フラットリストでrenderできないの?」
- フロントエンドはページネーションが必要だったが、バックエンドは実装していなかった。
- エラーメッセージは曖昧で、デバッグはブレークポイントとJSONの探索を意味していた。
- 1つのエンドポイントが3つのスクリーンで使われ、それぞれ異なるフィールドが期待されていた。
結局、APIを5回も書き直すことになり、SlackでJSONペイロードをポケモンカードのように交換しました。ローンチが2週間遅延し、PMは仕様を書き直し、QAは変更を追いかけていました。上司まで現れて言いました。
「ページは出来上がっているのに、なぜAPIがまだ機能しないんだ?」
それ以来、私たちチームは全員で誓約しました。
API設計が最優先。絶対に。
API優先≠「コードを書いてからドキュメントを追加する」
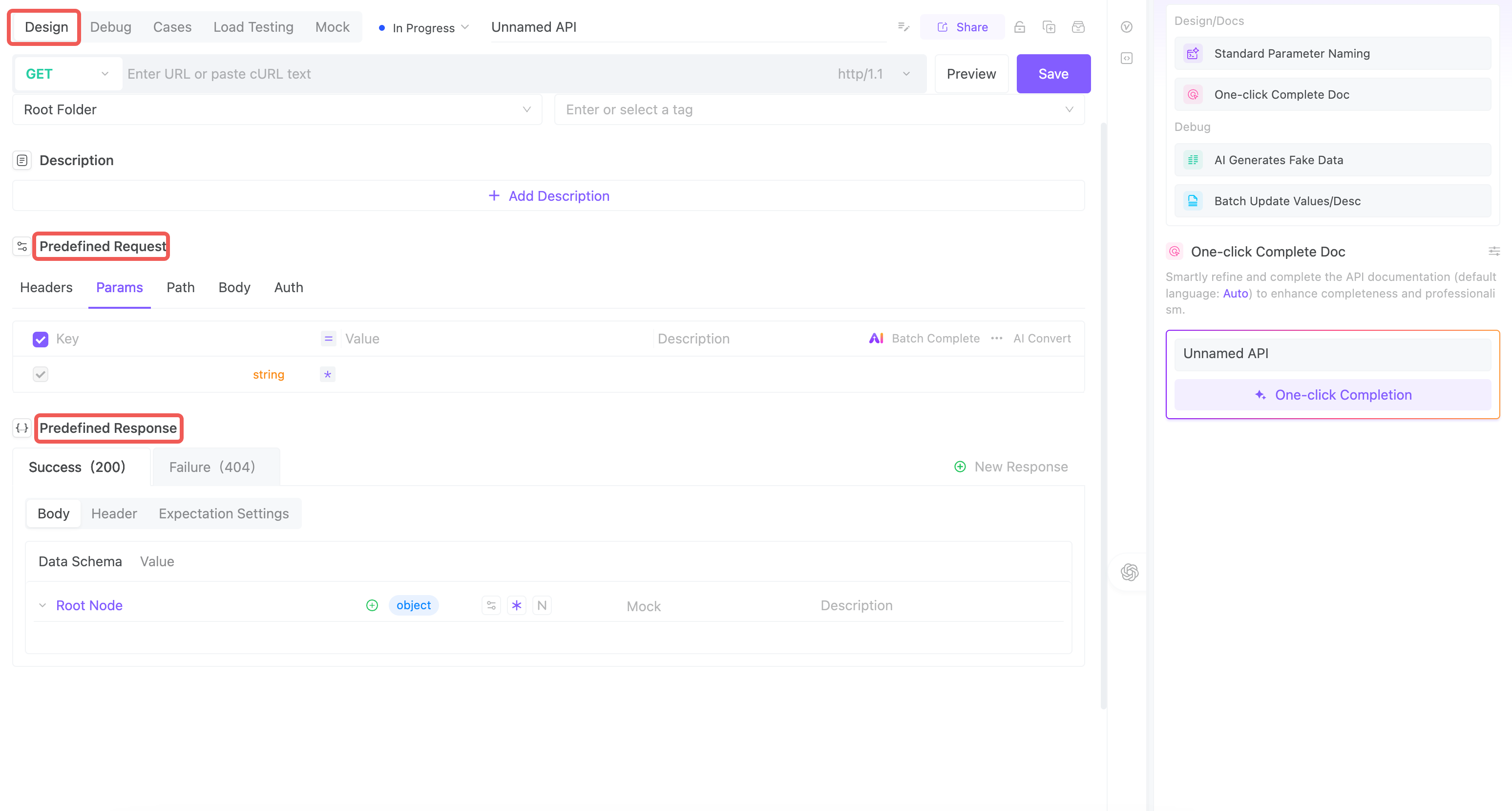
私たちはEchoAPIのAPI優先ワークフローを導入しました。以下のような考え方が変わりました:
- ❌ Not:「まずバックエンドを書いて、最後にSwaggerファイルを追加する。」
- ✅ Yes:EchoAPIでロジックを一行も書く前にAPIを定義する。
フィールド名、構造、フォーマット、ステータスコード、ページネーションルール——すべてを最初に明確に設計する。
以下が私たちの新しいやり方です——新しい機能は以下の3つのAPI優先ステップから始める:
1. コードに触れる前にAPIを定義する
これは基礎です:パス、メソッド、リクエストの形。私たちはこれをAPIモデリングと呼びます——家を建てる前にブループリントを描くようなものです。
先ほどの機能を例にとります:
「ユーザー行動分析」モジュールを構築し、活動トレンド、地域、访问回数などを表示する。
最終的な結果は次のようになりました:
GET /api/users/stats
どのように分解したかを説明します:
ステップ1:メソッドを選択する——GET
このAPIはデータを取得するため、GETを選びました。
なぜGETなのか?
- 意図が明確:読み取り専用
- ブラウザのネイティブキャッシュ
- URLにクエリパラメータが表示されるためデバッグが容易
ステップ2:パスの命名——/api/users/stats
URLを意味的でRESTfulにしました:
/api/users→ リソース:ユーザー/stats→ サブリソース:ステータス
/getUserStatsとしない理由は、関数を呼び出しているのではなくリソースにアクセスしているからです。
メリット?
- クリーンで拡張性が高い(例えば、後の
/export) - ドキュメント、RBAC、モックツールに優しい
ステップ3:クエリパラメータを設計する
GET /api/users/stats?date_range=2024-01-01_to_2024-01-31&type=region&page=1&page_size=10
| パラメータ | タイプ | 説明 |
|---|---|---|
date_range |
string | 日付範囲、例えば2024-01-01_to_2024-01-31 |
type |
string | region, active, visitなど |
page |
number | ページ番号 |
page_size |
number | 1ページあたりのアイテム数 |
なぜこれを使うのか:
- クエリストリングはフィルタリング/ソート/ページネーションに最適
- フロントエンドのコントロール(日付ピッカー、ドロップダウン、ページネータ)と整合性がある
- キャッシュしやすく、SEOに優しい
このステップからの出力:
| 納品物 | 例 |
|---|---|
| APIパス | GET /api/users/stats |
| クエリパラメータ仕様 | date_range: string, type: enum, page: number |
2. スキーマを事前に定義する:リクエスト+レスポンスのレビューを誰もコードを書く前に行う
これはAPI優先のMVPです:明確に構造化されたリクエスト/レスポンス契約。私たちはこれをスキーマレビューと呼び、これをスキップすることはローラーコースターのボルトをスキップすることに等しい。
なぜこれほど重要なのか?
✅ バックエンドとフロントエンドが構造に合意する
✅ フロントエンドは早期にモックでき、バックエンドのボトルネックなし
✅ フィールド名の変更の往復を避ける
✅ 新しい開発者を「ソースを読んで祈る」ことなくオンボーディングできる
ツールステップ1:リクエストスキーマを設計する
例えば、POST /api/user/queryを使って行動統計を取得する場合。
{
"date_range": ["2024-01-01", "2024-01-31"],
"type": "region",
"region_filter": ["Northeast", "West Coast"],
"min_active_users": 50,
"sort_by": "active_users",
"order": "desc",
"page": 1,
"page_size": 10
}
| フィールド | タイプ | 必須 | 説明 |
|---|---|---|---|
date_range |
array | ✅ | [start, end]フォーマット、YYYY-MM-DD |
type |
string | ✅ | 集計次元:region, trendなど。 |
region_filter |
array | ❌ | ["Northeast", "Midwest"]のような地域フィルター |
min_active_users |
number | ❌ | 最小しきい値 |
sort_by |
string | ❌ | ソートするフィールド |
order |
string | ❌ | ascまたはdesc |
page |
number | ❌ | デフォルトは1 |
page_size |
number | ❌ | デフォルトは10、最大100 |
ツールステップ2:レスポンスを標準化する
私たちは普遍的なレスポンス構造を強制しています:
{
"code": 100000,
"message": "success",
"data": {
"items": [
{
"region": "West Coast",
"active_users": 120,
"trend": [32, 44, 55, 65, 78]
}
],
"page": 1,
"page_size": 10,
"total": 67
}
}
| フィールド | タイプ | 必須 | 説明 |
|---|---|---|---|
code |
number | ✅ | ステータスコード;100000は成功を示します |
message |
string | ✅ | ユーザーへのフィードバックやデバッグ用メッセージ(失敗時) |
data.items |
array | ✅ | 事業データのリスト、各アイテムは統計レコードです |
data.items[].region |
string | ✅ | 地域名、例えば |
data.items[].active_users |
number | ✅ | アクティブユーザー数 |
data.items[].trend |
array | ❌ | トレンドデータの配列(例:日次、週次、月次) |
data.page |
number | ❌ | ページネーションAPIの現在のページ番号(それ以外はオプション) |
data.page_size |
number | ❌ | ページネーションAPIの1ページあたりのアイテム数(オプション) |
data.total |
number | ❌ | アイテムの総数(総ページ数を計算するために使用) |
ツールステップ3:レビュー
定義した後、フロントエンド、バックエンド、QAチームを集め、以下の主要なレビュー項目について議論します:
| レビューアイテム | 例の質問 |
|---|---|
| フィールドの意味が明確ですか? | regionはprovinceまたはcityにさらに指定すべきですか? |
| データ構造は合理的ですか? | trendはタイムスタンプを含め、[{ x: "2024-01-01", y: 88 }]のようなオブジェクトの配列に変更すべきですか? |
| ネーミング規則は一貫していますか? | user_idとuserIdのような不一致や曖昧さはありますか? |
| ネestingが深すぎるか不明=<?=か? | data.items[].trendは合理的ですか、それともフラットにすべきですか? |
| レスポンスフィールドはフロントエンドの表示要件を満たしていますか? | active_countは十分ですか?inactive_countなどが必要ですか? |
| ページネーション、ソート、フィルタリングは容易ですか? | total、page、およびpage_sizeは存在していますか?ソート可能なフィールドは構成可能ですか? |
合意に達した後、スキーマをロックし→モックを生成→契約を作成します。
スキーマの変更是契約の更新を意味します。サプライズはありません。
3. 統一されたエラーコードを設計する
エラー応答の例:
{
"code": 40001,
"message": "Invalid parameter: date_range is required",
"data": null
}
| コード | 意味 | HTTPコード | 使用例 |
|---|---|---|---|
| 100000 | 成功 | 200 | すべて正常に行いました |
| 40001 | パラメータ検証 | 400 | フィールドが欠けている、型が無効です |
| 40101 | 認証失敗 | 401 | トークンが期限切れまたはログインしていない |
| 40301 | アクセス拒否 | 403 | 権限が不十分です |
| 50000 | サーバーエラー | 500 | おっと、処理されない例外です |
常に役立つメッセージを含めましょう——フロントエンドがユーザーになぜエラーが発生したかを表示できるように。
EchoAPIを採用してAPI優先を実践した後、何が変わったのか?
| カテゴリ | ベネフィット | 説明 |
|---|---|---|
| コラボレーション | スキーマ=共有の真実 | フィールド名を推測したり、スクリーンショットの戦争をすることなくなりました |
| モックを契約として=並行開発 | フロントエンドはデー1からモックに対して構築します | |
| ドキュメントと例=更好的QA | テスターはコードを読まずに検証できます | |
| 人≠プロセス——API≠人 | 契約に基づくワークフローは部族知識に頼りません | |
| 再利用性 | 標準レスポンス=再利用可能なロジック | すべてのエラー処理を一元化しました |
| 一貫したインターフェース=スケーリングが容易 | さらにプラグアンドプレイ、カスタム接着剤が少なくなります | |
| 穏やか | 早期に問題をキャッチ | コーディング前にネーミング/構造の不一致を修正します |
| すべての変更をトラック | バージョン管理 | |
| 硬い構造=バグが少なく | nullが少なく、サプライズが少なくなります | |
| 自動化 | 1つのスキーマ=多くの出力 | ドキュメント、モック、バリデーターを単一ソースから生成します |
| ツールに優しい | 監視、テスト、ドキュメントにシームレスに接続できます |
スキーマは契約です。モックはテストです。標準は盾です。
API優先は無駄な仕事ではありません——混沌から協力を達成する方法なのです。
EchoAPIのAPI優先はツールではなく、チームの成熟度についてです
人々はEchoAPIが「ただの開発ツール」と思っています。違います。
それは実際の、古い問題を解決します:
- 推測が少なく
- やり直しが少なく
- 混沌が少なく
住宅建设する就像是——あなたはコンクリートを流し込む前にブループリントが必要です。
どのフィールドがビルドを壊したのかを忘れるかもしれませんが...
APIがプロダクションで爆発した後の2時デバッグセッションを決して忘れないでしょう。
「インテgrationデー」が「調査デー」になるのを待たないでください。
次回はEchoAPIから始め——プロ並みにリリースしましょう。
